Who?
- Unit of Lehigh's Library & Technology Services within the Center for Innovation in Teaching & Learning
Our Mission
- We enable Lehigh Faculty, Researchers and Scholars achieve their goals by providing various computational resources; hardware, software, and storage; consulting and training.
Research Computing Staff
- Alex Pacheco, Manager & XSEDE Campus Champion
- Steve Anthony, System Administrator
- Dan Brashler, CAS Senior Computing Consultant
- Sachin Joshi, Data Analyst & Visualization Specialist
Introduction to Linux & HPC
Research Computing, Library & Technology Services
https://researchcomputing.lehigh.edu
About Us?
What do we do?
- Hardware Support
- Provide system administration and support for Lehigh's HPC clusters.
- 1 University owned and 3 Faculty owned
- Assist with purchase, installation and administration of servers and clusters.
- Provide system administration and support for Lehigh's HPC clusters.
- Data Storage
- Provide data management services including storing and sharing data.
- Software Support
- Provide technical support for software applications, install software as requested and assist with purchase of software.
- Training & Consulting
- Provide education and training programs to facilitate use of HPC resources and general scientific computing needs.
- Provide consultation and support for code development and visualization.
Research Computing Resources
- Sol
- Lehigh's Flagship High Performance Computing Cluster
- 9 nodes, dual 10-core Intel Xeon E5-2650 v3 2.3GHz CPU, 25MB Cache, 128GB RAM
- 33 nodes, dual 12-core Intel Xeon E5-2670 v3 2.3Ghz CPU, 30 MB Cache, 128GB RAM
- 14 nodes, dual 12-core Intel Xeon E5-2650 v4 2.3Ghz CPU, 30 MB Cache, 64GB RAM
- 1 node, dual 8-core Intel Xeon 2630 v3 2.4GHz CPU, 20 MB Cache, 512GB RAM
- 24 nodes, dual 18-core Intel Xeon Gold 6140 2.3GHz CPU, 24.7 MB Cache, 192GB RAM
- 6 nodes, dual 18-core Intel Xeon Gold 6240 2.6GHz, 24.75 MB Cache, 192GB RAM
- 72 nVIDIA GTX 1080 & 48 nVIDIA RTX 2080TI GPU cards
- 1TB HDD per node
- 2:1 oversubscribed Infiniband EDR (100Gb/s) interconnect fabric
- Theoretical Performance: 93.184 TFLOPs (CPU) + 36.130 TFLOPs (GPU)
LTS Managed Faculty Resources
- Monocacy: Ben Felzer, Earth & Environmental Sciences
- Eight nodes, dual 8-core Intel Xeon E5-2650v2, 2.6GHz, 64GB RAM
- Theoretical Performance: 2.662TFlops
- Eight nodes, dual 8-core Intel Xeon E5-2650v2, 2.6GHz, 64GB RAM
- Baltrusaitislab: Jonas Baltrusaitis, Chemical Engineering
- Three nodes, dual 16-core AMD Opteron 6376, 2.3Ghz, 128GB RAM
- Theoretical Performance: 1.766TFlops
- Three nodes, dual 16-core AMD Opteron 6376, 2.3Ghz, 128GB RAM
- Pisces: Keith Moored, Mechanical Engineering and Mechanics
- Six nodes, dual 10-core Intel Xeon E5-2650v3, 2.3GHz, 64GB RAM, nVIDIA Tesla K80
- Theoretical Performance: 4.416 TFlops (CPU) + 17.46TFlops (GPU)
- Six nodes, dual 10-core Intel Xeon E5-2650v3, 2.3GHz, 64GB RAM, nVIDIA Tesla K80
- Pavo : decommissioned faculty cluster for prototyping future resources
- Twenty nodes, dual 8-core Intel Xeon E5-2650v2, 2.6GHz, 64GB RAM
- Theoretical Performance: 6.656TFlops
- 3 nodes available for 1 hour debug runs.
- Twenty nodes, dual 8-core Intel Xeon E5-2650v2, 2.6GHz, 64GB RAM
Total Computational Resources Supported
| Cluster | Cores | CPU Memory | CPU TFLOPs | GPUs | CUDA Cores | GPU Memory | GPU TFLOPS |
|---|---|---|---|---|---|---|---|
| Monocacy | 128 | 512 | 2.662 | 0 | 0 | 0 | 0.000 |
| Pavo | 320 | 1280 | 6.656 | 0 | 0 | 0 | 0.000 |
| Baltrusaitis | 96 | 384 | 1.766 | 0 | 0 | 0 | 0.000 |
| Pisces | 120 | 384 | 3.840 | 12 | 29952 | 144 | 17.422 |
| Sol | 2404 | 12544 | 93.184 | 120 | 393216 | 1104 | 36.130 |
| Total | 3068 | 15104 | 108.108 | 132 | 423168 | 1248 | 53.552 |
- Monocacy, Baltrusaitis and Pisces: decommissioning scheduled for Sep 30, 2021.
Accessing Research Computing Resources
Sol: accessible using ssh while on Lehigh's network
ssh username@sol.cc.lehigh.eduIf you are not on Lehigh's network, login to the ssh gateway
ssh username@ssh.cc.lehigh.eduand then login to sol as above
- Alternatively,
ssh -J username@ssh.cc.lehigh.edu username@sol.cc.lehigh.edu- Click here to learn how to configure MobaXterm to use the SSH Gateway.
Open Ondemand
- Open, Interactive HPC via the Web
- Easy to use, plugin-free, web-based access to supercomputers
- File Management
- Command-line shell access
- Job management and monitoring
- Various Applications
- NSF-funded project
- SI2-SSE-1534949 and CSSI-Software-Frameworks-1835725
- Ohio Supercomputing Center
- Deployed at dozens of sites (universities, supercomputing centers)
- At Lehigh: https://hpcportal.cc.lehigh.edu
- Lehigh IP or VPN required
What about Storage resources
- LTS provides various storage options for research and teaching.
- Some are cloud based and subject to Lehigh's Cloud Policy.
- For research, LTS provides a 768TB storage system called Ceph.
- Ceph is based on the Ceph software.
- Research groups can purchase a sharable project space on Ceph @ $375/TB with a 5 year duration.
- Ceph is in-house, built, operated and administered by LTS Research Computing Staff.
- located in Data Center in EWFM with a backup cluster in Packard Lab
- HPC users can write job output directly to their Ceph volume
- Ceph volume can be mounted as a network drive on Windows or CIFS on Mac and Linux
- See Ceph FAQ for more details
- Annual HPC User account fees waived for PIs who purchase a 1TB Ceph space for life of Ceph i.e. 5 years
Network Layout Sol & Ceph Storage Cluster
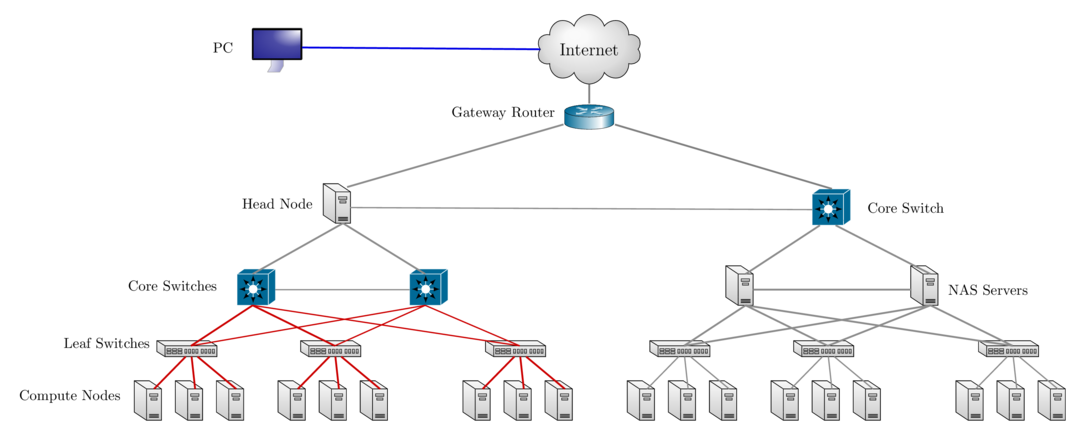
How do I get started using HPC resources for this course
Login to sol using the SSH Client or the web portal
Linux is the Operating System installed on all HPC resources.
- You should see something like
[alp514@sol ~]$if you are logged into sol - This is known as the command prompt
- sol is the head/login for the cluster.
- Do not run computation on this node.
- Editing files, compiling code are acceptable computation on this node.
- Running intense computation on this node causes a high load on the storage that would cause other users jobs to run slow.
- You should see something like
What is Linux?
- Linux is an operating system that evolved from a kernel created by Linus Torvalds when he was a student at the University of Helsinki.
- It’s meant to be used as an alternative to other operating systems, Windows, Mac OS, MS-DOS, Solaris and others.
- Linux is the most popular OS used in a Supercomputer
| OS Family | Count | Share % |
|---|---|---|
| Linux | 498 | 99.6 |
| Unix | 2 | .4 |
- If you are using a Supercomputer/High Performance Computer for your research, it will be based on a *nix OS.
- It is required/neccessary/mandatory to learn Linux Programming (commands, shell scripting) if your research involves use of High Performance Computing or Supercomputing resources.
Where is Linux used?
- Linux distributions are tailored to different requirements such as
- Server
- Desktop
- Workstation
- Routers
- Embedded devices
- Mobile devices (Android is a Linux-based OS)
- Almost any software that you use on windows has a roughly equivalent software on Linux, most often multiple equivalent software
- e.g. Microsoft Office equivalents are OpenOffice.org, LibreOffice, KOffice
- Visit for complete list
- Linux offers you freedom, to choose your desktop environment, software.
What is a Linux OS, Distro, Desktop Environment?
- Many software vendors release their own packaged Linux OS (kernel, applications) known as distribution
- Linux distribution = Linux kernel + GNU system utilities and libraries + Installation scripts + Management utilities etc.
- Debian, Ubuntu, Mint
- Red Hat, Fedora, CentOS
- Slackware, openSUSE, SLES, SLED
- Gentoo
- Application packages on Linux can be installed from source or from customized packages
- deb: Debian based distros e.g. Debian, Ubuntu, Mint
- rpm: Red Hat based distros, Slackware based distros.
- Linux distributions offer a variety of desktop environment.
- K Desktop Environment (KDE)
- GNOME
- XFCE
- Lightweight X11 Desktop Environment (LXDE)
- Cinnamon
- MATE
- Dynamic Window Manager
Difference between Shell and Command
- What is a Shell?
- The command line interface is the primary interface to Linux/Unix operating systems.
- Shells are how command-line interfaces are implemented in Linux/Unix.
- Each shell has varying capabilities and features and the user should choose the shell that best suits their needs.
- The shell is simply an application running on top of the kernel and provides a powerful interface to the system.
- What is a command and how do you use it?
- command is a directive to a computer program acting as an interpreter of some kind, in order to perform a specific task.
- command prompt (or just prompt) is a sequence of (one or more) characters used in a command-line interface to indicate readiness to accept commands.
- Its intent is to literally prompt the user to take action.
- A prompt usually ends with one of the characters $, %, #, :, > and often includes other information, such as the path of the current working directory.
Types of Shell
- sh : Bourne Shell
- Developed by Stephen Bourne at AT&T Bell Labs
- csh : C Shell
- Developed by Bill Joy at University of California, Berkeley
- ksh : Korn Shell
- Developed by David Korn at AT&T Bell Labs
- backward-compatible with the Bourne shell and includes many features of the C shell
- bash : Bourne Again Shell
- Developed by Brian Fox for the GNU Project as a free software replacement for the Bourne shell (sh).
- Default Shell on Linux and Mac OSX
- tcsh : TENEX C Shell
- Developed by Ken Greer at Carnegie Mellon University
- It is essentially the C shell with programmable command line completion, command-line editing, and a few other features.
Directory Structure
- All files are arranged in a hierarchial structure, like an inverted tree.
- The top of the hierarchy is traditionally called root (written as a slash / )
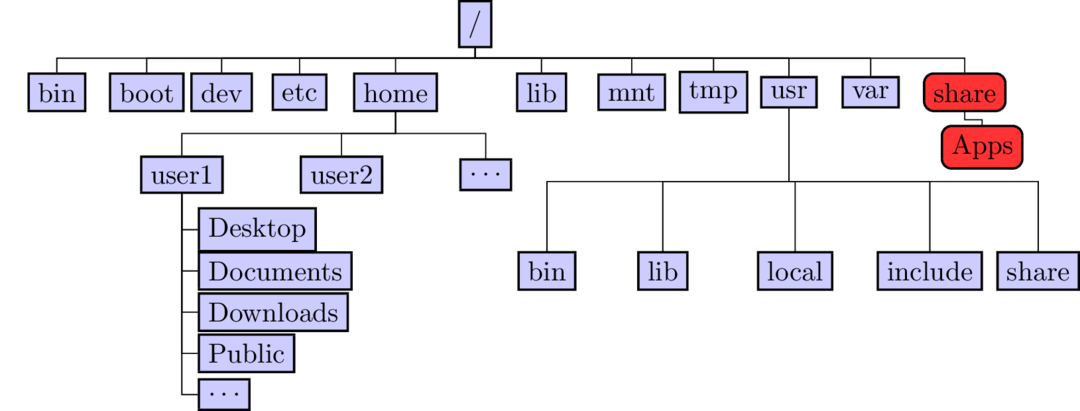
Relative & Absolute Path
- Path means a position in the directory tree.
- You can use either the relative path or absolute path
- In relative path expression
- (one dot or period) is the current working directory
- (two dots or periods) is one directory up
- You can combine . and .. to navigate the filee system hierarchy.
- the path is not defined uniquely and does depend on the current path.
- is unique only if your current working directory is your home directory.
- In absolute path expression
- the path is defined uniquely and does not depend on the current path
- /tmp is unique since /tmp is the abolute path
Some Linux Terms (also called variables)
- HOME : Your Home Directory on the system, /home/username
- This is where you should be when you login the first time
- Don't believe me, type
pwdand hit enter
- PATH : List of directories to search when executing a command
- Enter
avogadroat the command prompt - You should see an error saying
command not found
- Enter
- LD_LIBRARY_PATH : List of directories to look for libraries executing code
Linux Commands
manshows the manual for a command or program.man pwd
pwd: print working directory, gives the absolute path of your current location in the directory hierarchyecho: prints whatever follows to the screenecho $HOME: prints the contents of the variable HOME i.e. your home directory to the screen
cd dirname: change to folder calleddirname- default
dirnameis your home directory - Useful option
cd -go to previous directory
- default
mkdir dirname: create a directory calleddirname- Create a directory, any name you want and cd to that directory
mkdir me450followed bycd me450
- Useful option
mkdir -p dir1/dir2/dir3create intermediate directories if they do not exist
- Create a directory, any name you want and cd to that directory
Linux Command (contd)
cp file1 file2: command to copy file1 to file2- Useful options:
cp -r /home/alp514/Workshop/sum2017 .copy directories recursivelycp -p ~alp514/in.lj ${HOME}/preserve time stamps
- Useful options:
rm file1: delete a file called file1- Useful options
rm -ito be prompted for confirmationrm -rto delete directories recursivelyrm -fdelete without prompting - VERY DANGEROUS
- Useful options
ls dirname: list contents of dirname (leave blank for current directory)- Useful options
ls -lshow long form listingls -ashow hidden filesls -tsort by timestamp newest first, best when combined with-lls -rreverse sort (default alphabetical), best when combined with-l -tor-lt
- Useful options
alias: create a shortcut to another command or name to execute a long string.alias rm="/bin/rm -i"
File Editing
- The two most commonly used editors on Linux/Unix systems are:
- vi or vim (vi improved)
- emacs
- vi/vim is installed by default on Linux/Unix systems and has only a command line interface (CLI).
- emacs has both a CLI and a graphical user interface (GUI).
- Other editors that you may come across on *nix systems
- kate: default editor for KDE.
- gedit: default text editor for GNOME desktop environment.
- gvim: GUI version of vim
- pico: console based plain text editor
- nano: GNU.org clone of pico
- kwrite: editor by KDE.
vi commands
| Inserting/Appending Text | Command |
|---|---|
| insert at cursor | i |
| insert at beginning of line | I |
| append after cursor | a |
| append at end of line | A |
| newline after cursor in insert mode | o |
| newline before cursor in insert mode | O |
| append at end of line | ea |
| exit insert mode | ESC |
| Cursor Movement | Command |
|---|---|
| move left | h |
| move down | j |
| move up | k |
| move right | l |
| jump to beginning of line | ^ |
| jump to end of line | $ |
| goto line n | nG |
| goto top of file | 1G |
| goto end of file | G |
| move one page up | CNTRL-u |
| move one page down | CNTRL-d |
vi commands
| File Manipulation | Command |
|---|---|
| save file | :w |
| save file and exit | :wq |
| quit | :q |
| quit without saving | :q! |
| delete a line | dd |
| delete n lines | ndd |
| paste deleted line after cursor | p |
| paste before cursor | P |
| undo edit | u |
| delete from cursor to end of line | D |
| File Manipulation | Command |
|---|---|
| replace a character | r |
| join next line to current | J |
| change a line | cc |
| change a word | cw |
| change to end of line | c$ |
| delete a character | x |
| delete a word | dw |
| edit/open file | :e file |
| insert file | :r file |
Available Software
- A variety of commercial, free and open source software is available
- Software is managed using module environment
- Why? We may have different versions of same software or software built with different compilers
- Module environment allows you to dynamically change your *nix environment based on software being used
- Standard on many University and national High Performance Computing resource since circa 2011
- LTS provides licensed and open source software for Windows, Mac and Linux and Gogs, a self hosted Git Service or Github clone
Module Command
| Command | Description |
|---|---|
module avail |
show list of software available on resource |
module load abc |
add software abc to your environment (modify your PATH, LD_LIBRARY_PATH etc as needed) |
module unload abc |
remove abc from your environment |
module swap abc1 abc2 |
swap abc1 with abc2 in your environment |
module purge |
remove all modules from your environment |
module show abc |
display what variables are added or modified in your environment |
module help abc |
display help message for the module abc |
- Users who prefer not to use the module environment will need to modify their
.bashrc or .tcshrc files. Run
module showfor list variables that need modified, appended or prepended
Installed Software
- Chemistry/Materials Science
- CPMD
- GAMESS
- Gaussian
- NWCHEM
- Quantum Espresso
- VASP (Restricted Access)
- Molecular Dynamics
- Desmond
- GROMACS
- LAMMPS
- NAMD
MPI enabled
- Computational Fluid Dynamics
- Abaqus
- Ansys
- Comsol
- OpenFOAM
- OpenSees
- Math
- GNU Octave
- Magma
- Maple
- Mathematica
- MATLAB
- SAS
More Software
Machine & Deep Learning
- TensorFlow
- Caffe
- SciKit-Learn
- SciKit-Image
- Theano
- Keras
Natural Language Processing (NLP)
- Natural Language Toolkit (NLTK)
- Stanford NLP
- Bioinformatics
- BamTools
- BayeScan
- bgc
- BWA
- FreeBayes
- SAMTools
- tabix
- trimmomatic
- Trinity
- barcode_splitter
- phyluce
- VelvetOptimiser
More Software
- Scripting Languages
- R
- Perl
- Python
- Compilers
- GNU
- Intel
- JAVA
- PGI/NVIDIA HPC SDK
- CUDA
- Parallel Programming
- MVAPICH2
- MPICH
- OpenMPI
- Libraries
- BLAS/LAPACK/GSL/SCALAPACK
- Boost
- FFTW
- Intel MKL
- HDF5
- NetCDF
- METIS/PARMETIS
- PetSc
- QHull/QRupdate
- SuiteSparse
- SuperLU
More Software
- Visualization Tools
- Atomic Simulation Environment
- Avogadro
- GaussView
- GNUPlot
- PWGui
- PyMol
- RDKit
- VESTA
- VMD
- XCrySDen
- Other Tools
- Artleys Knitro
- ROOT
- CMake
- GNU Parallel
- Lmod
- Numba
- Scons
- SPACK
- MD Tools
- BioPython
- CCLib
- MDAnalysis
Open OnDemand Applications
- Jupyter Notebooks
- RStudio
- Ansys Workbench
- Abaqus CAE
- GNU Octave
- Maple
- Mathematica
- MATLAB
- SAS
- VMD
- Virtual Desktops (MATE and XFCE)
- Visualization
- ASE
- Avogadro
- Blender
- Gabedit
- Gauss View
- Paraview
- PWGui
- PyMol
- VESTA
- XCrySDen
Using your own Software?
- You can always install a software in your home directory
- SPACK is an excellent package manager that can even create module files
Stay compliant with software licensing- Modify your .bashrc/.tcshrc to add software to your path, OR
- create a module and dynamically load it so that it doesn't interfere
with other software installed on the system
- e.g. You might want to use openmpi instead of mvapich2
- the system admin may not want install it system wide for just one user
- Add the directory where you will install the module files to the variable MODULEPATH in .bashrc/.tcshrc
# My .bashrc file
export MODULEPATH=${MODULEPATH}:/home/alp514/modulefiles
Module File Example
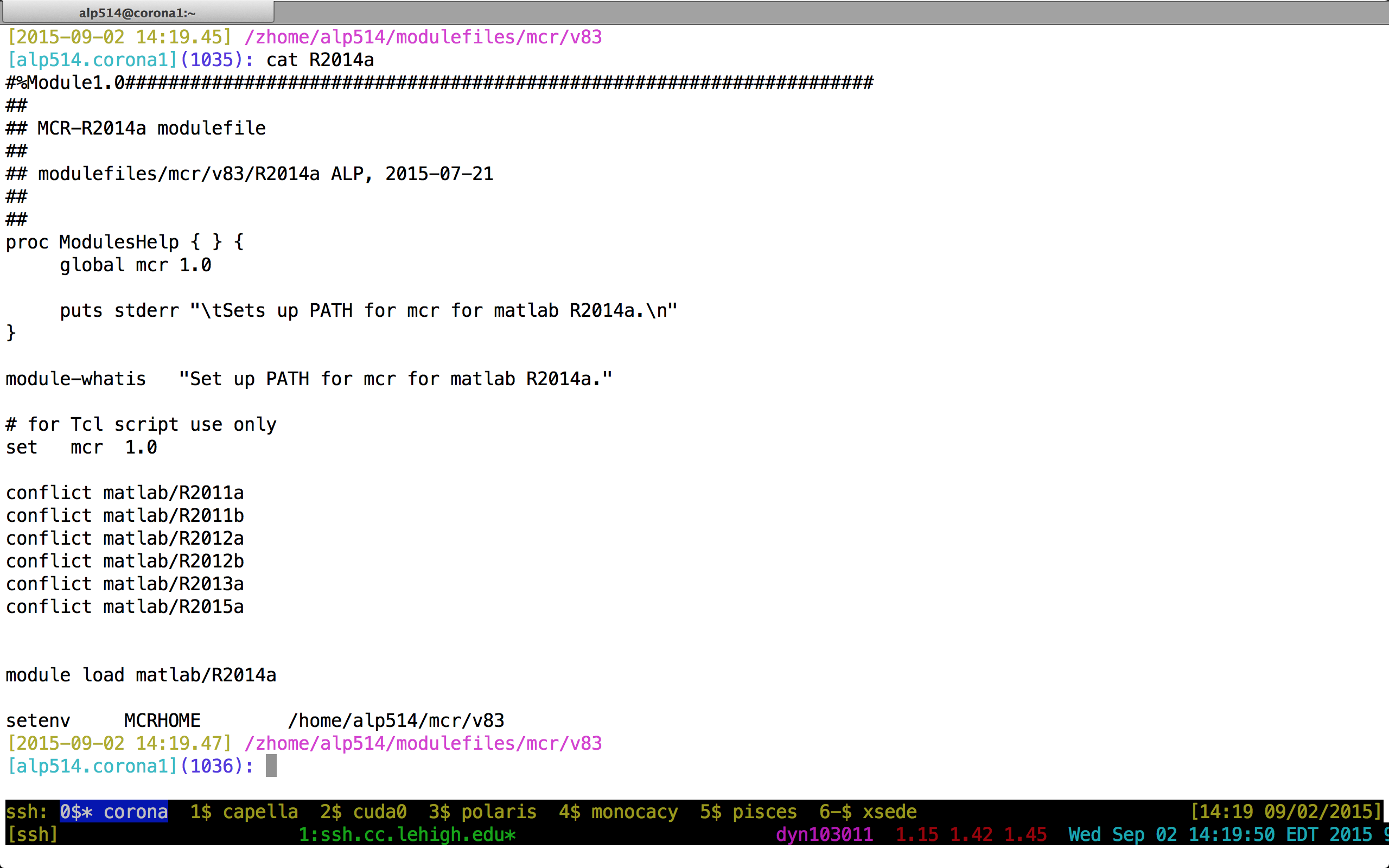
Cluster Environment
- A cluster is a group of computers (nodes) that works together closely
Two types of nodes
- Head/Login Node
- Compute Node
Multi-user environment
Each user may have multiple jobs running simultaneously
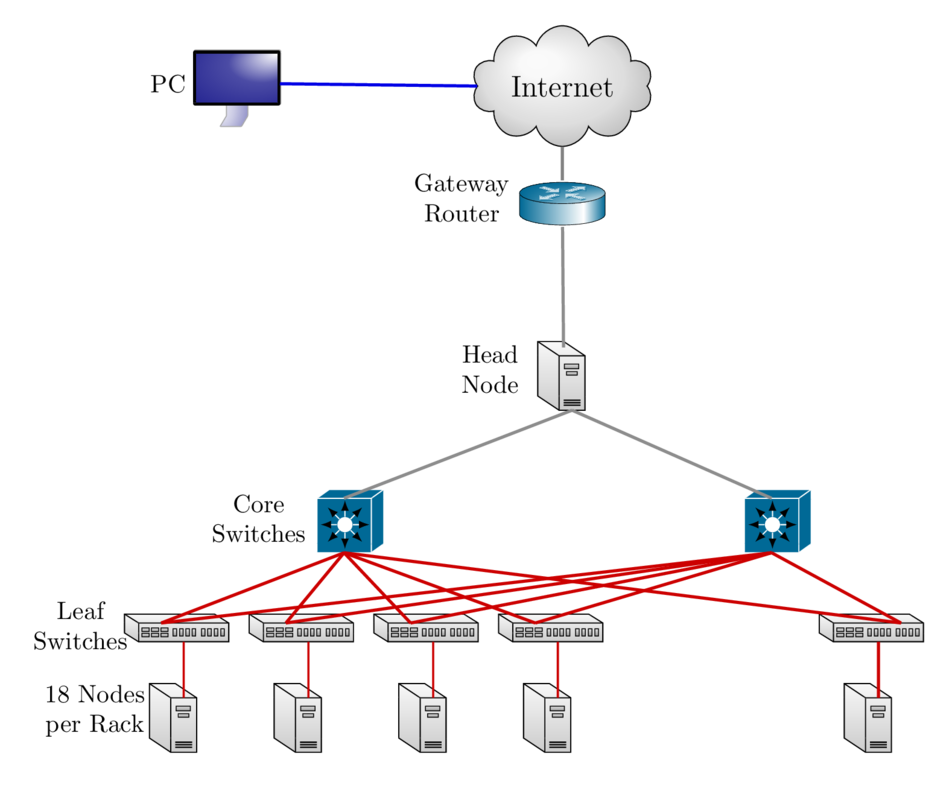
How to run jobs
- All compute intensive jobs are scheduled
- Write a script to submit jobs to a scheduler
- need to have some background in shell scripting (bash/tcsh)
- Need to specify
- Resources required (which depends on configuration)
- number of nodes
- number of processes per node
- memory per node
- How long do you want the resources
- have an estimate for how long your job will run
- Which queue to submit jobs
- SLURM uses the term partition instead of queue
- Resources required (which depends on configuration)
Scheduler & Resource Management
A software that manages resources (CPU time, memory, etc) and schedules job execution
- Sol: Simple Linux Utility for Resource Management (SLURM)
- Others: Portable Batch System (PBS)
- Scheduler: Maui
- Resource Manager: Torque
- Allocation Manager: Gold
A job can be considered as a user’s request to use a certain amount of resources for a certain amount of time
The Scheduler or queuing system determines
- The order jobs are executed
- On which node(s) jobs are executed
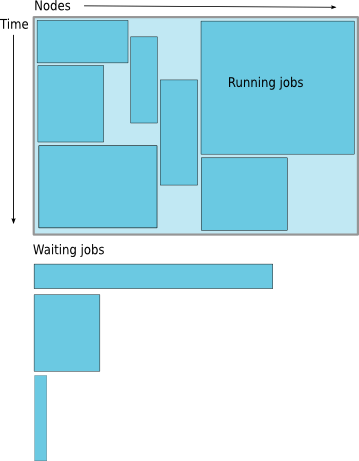
Job Scheduling
Map jobs onto the node-time space
- Assuming CPU time is the only resource
Need to find a balance between
- Honoring the order in which jobs are received
- Maximizing resource utilization
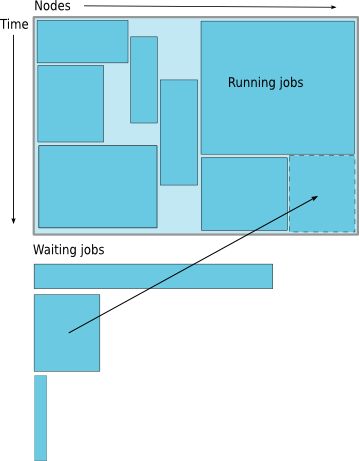
Backfilling
- A strategy to improve utilization
- Allow a job to jump ahead of others when there are enough idle nodes
- Must not affect the estimated start time of the job with the highest priority
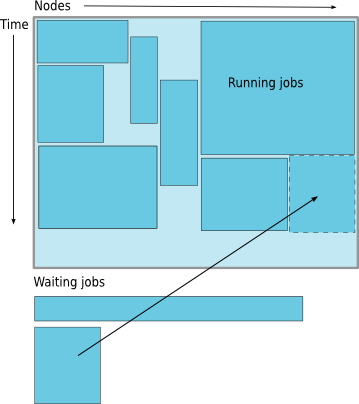
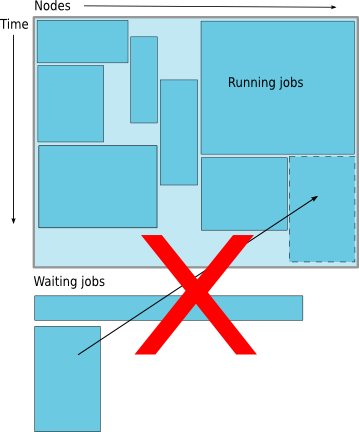
How much time must I request
- Ask for an amount of time that is
- Long enough for your job to complete
- As short as possible to increase the chance of backfilling
Available Queues
| Partition Name | Max Runtime in hours | Max SU consumed node per hour |
|---|---|---|
| lts | 72 | 18 |
| lts-gpu | 72 | 20 |
| im1080 | 48 | 20 |
| im1080-gpu | 48 | 24 |
| eng | 72 | 22 |
| eng-gpu | 72 | 24 |
| engc | 72 | 24 |
| himem | 72 | 48 |
| enge/engi/chem/health | 72 | 36 |
| im2080 | 48 | 28 |
| im2080-gpu | 48 | 36 |
| debug | 1 | 16 |
How much memory can or should I use per core?
The amount of installed memory less the amount that is used by the operating system and other utilities
A general rule of thumb on most HPC resources: leave 1-2GB for the OS to run.
| Cluster | Partition | Max Memory/core (GB) | Recommended Memory/Core (GB) |
|---|---|---|---|
| Sol | lts | 6.4 | 6.2 |
| eng/im1080/im1080-gpu/enge/engi/im2080/im2080-gpu/chem/health | 5.3 | 5.1 | |
| engc | 2.66 | 2.4 | |
| debug | 4 | 3.8 |
- if you need to run a single core job that requires 10GB memory in the eng partition, you need to request 2 cores even though you are only using
1 core.
Useful SBATCH Directives
| SLURM Directive | Description |
|---|---|
| #SBATCH --partition=queuename | Submit job to the queuename partition. |
| #SBATCH --time=hh:mm:ss | Request resources to run job for hh hours, mm minutes and ss seconds. |
| #SBATCH --nodes=m | Request resources to run job on m nodes. |
| #SBATCH --ntasks-per-node=n | Request resources to run job on n processors on each node requested. |
| #SBATCH --ntasks=n | Request resources to run job on a total of n processors. |
| #SBATCH --job-name=jobname | Provide a name, jobname to your job. |
| #SBATCH --output=filename.out | Write SLURM standard output to file filename.out. |
| #SBATCH --error=filename.err | Write SLURM standard error to file filename.err. |
| #SBATCH --mail-type=events | Send an email after job status events is reached. |
| events can be NONE, BEGIN, END, FAIL, REQUEUE, ALL, TIME_LIMIT(_90,80) | |
| #SBATCH --mail-user=address | Address to send email. |
| #SBATCH --account=mypi | charge job to the mypi account |
Useful SBATCH Directives (contd)
| SLURM Directive | Description |
|---|---|
| #SBATCH --qos=nogpu | Request a quality of service (qos) for the job in imlab, engc partitions. |
| Job will remain in queue indefinitely if you do not specify qos | |
| #SBATCH --gres=gpu:# | Specifies number of gpus requested in the gpu partitions |
| You can request 1 or 2 gpus with a minimum of 1 core or cpu per gpu |
- SLURM can also take short hand notation for the directives
| Long Form | Short Form |
|---|---|
| --partition=queuename | -p queuename |
| --time=hh:mm:ss | -t hh:mm:ss |
| --nodes=m | -N m |
| --ntasks=n | -n n |
| --account=mypi | -A mypi |
| --job-name=jobname | -J jobname |
| --output=filename.out | -o filename.out |
SBATCH Filename Patterns
- sbatch allows for a filename pattern to contain one or more replacement symbols, which are a percent sign "%" followed by a letter (e.g. %j).
| Pattern | Description |
|---|---|
| %A | Job array's master job allocation number. |
| %a | Job array ID (index) number. |
| %J | jobid.stepid of the running job. (e.g. "128.0") |
| %j | jobid of the running job. |
| %N | short hostname. This will create a separate IO file per node. |
| %n | Node identifier relative to current job (e.g. "0" is the first node of the running job) This will create a separate IO file per node. |
| %s | stepid of the running job. |
| %t | task identifier (rank) relative to current job. This will create a separate IO file per task. |
| %u | User name. |
| %x | Job name. |
Useful SLURM environmental variables
| SLURM Command | Description |
|---|---|
| SLURM_SUBMIT_DIR | Directory where the qsub command was executed |
| SLURM_JOB_NODELIST | Name of the file that contains a list of the HOSTS provided for the job |
| SLURM_NTASKS | Total number of cores for job |
| SLURM_JOBID | Job ID number given to this job |
| SLURM_JOB_PARTITION | Queue job is running in |
| SLURM_JOB_NAME | Name of the job. |
Basic Job Manager Commands
- Submission
- Monitoring
- Manipulating
- Reporting
Job Types
- Interactive Jobs
- Set up an interactive environment on compute nodes for users
- Will log you into a compute node and wait for your prompt
- Purpose: testing and debugging code. Do not run jobs on head node!!!
- All compute node have a naming convention sol-[a,b,c]###
- head node is sol
- Batch Jobs
- Executed using a batch script without user intervention
- Advantage: system takes care of running the job
- Disadvantage: cannot change sequence of commands after submission
- Useful for Production runs
- Workflow: write a script -> submit script -> take mini vacation -> analyze results
- Executed using a batch script without user intervention
Job Types: Interactive
SLURM: Use
sruncommand with SBATCH Directives followed by--pty /bin/bashsrun --time=<hh:mm:ss> --nodes=<# of nodes> --ntasks-per-node=<# of core/node> -p <queue name> --pty /bin/bash- If you have
soltoolsmodule loaded, then useinteractwith at least one SBATCH Directiveinteract -t 20[Assumes-p lts -n 1 -N 18]
- If you have
Run a job interactively replace
--pty /bin/bash --loginwith the appropriate command.srun -t 20 -n 1 -p im1080 --qos=nogpu $(which lammps) -in in.lj -var x 1 -var n 1- Default values are 3 days, 1 node, 18 tasks per node and lts partition
Job Types: Batch
- Workflow: write a script -> submit script -> take mini vacation -> analyze results
Submitting Batch Jobs
sbatch filenamesbatchcan take the options for#SBATCHas command line argumentssbatch --time=1:00:00 --nodes=1 --ntasks-per-node=18 -p lts filename
Minimal submit script for Serial Jobs
#!/bin/bash
#SBATCH --partition=lts
#SBATCH --time=1:00:00
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1
#SBATCH --job-name myjob
cd ${SLURM_SUBMIT_DIR}
./myjob < filename.in > filename.out
Minimal submit script for MPI Job
#!/bin/bash
#SBATCH --partition=lts
#SBATCH --time=1:00:00
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=20
## For --partition=imlab,
### use --ntasks-per-node=22
### and --qos=nogpu
#SBATCH --job-name myjob
module load mvapich2
cd ${SLURM_SUBMIT_DIR}
srun ./myjob < filename.in > filename.out
exit
Minimal submit script for OpenMP Job
#!/bin/tcsh
#SBATCH --partition=eng
# Directives can be combined on one line
#SBATCH --time=1:00:00 --nodes=1 --ntasks-per-node=22
#SBATCH --job-name myjob
cd ${SLURM_SUBMIT_DIR}
# Use either
setenv OMP_NUM_THREADS 22
./myjob < filename.in > filename.out
# OR
OMP_NUM_THREADS=22 ./myjob < filename.in > filename.out
exit
Minimal submit script for LAMMPS GPU job
#!/bin/tcsh
#SBATCH --partition=im1080-gpu
# Directives can be combined on one line
#SBATCH --time=1:00:00
#SBATCH --nodes=1
# 1 CPU can be be paired with only 1 GPU
# 1 GPU can be paired with all 24 CPUs
#SBATCH --ntasks-per-node=1
#SBATCH --gres=gpu:1
# Need both GPUs, use --gres=gpu:2
#SBATCH --job-name myjob
cd ${SLURM_SUBMIT_DIR}
# Load LAMMPS Module
module load lammps/17nov16-gpu
# Run LAMMPS for input file in.lj
srun $(which lammps) -in in.lj -sf gpu -pk gpu 1 gpuID ${CUDA_VISIBLE_DEVICE}
exit
Monitoring & Manipulating Jobs
| SLURM Command | Description |
|---|---|
| squeue | check job status (all jobs) |
| squeue -u username | check job status of user username |
| squeue --start | Show estimated start time of jobs in queue |
| scontrol show job jobid | Check status of your job identified by jobid |
| scancel jobid | Cancel your job identified by jobid |
| scontrol hold jobid | Put your job identified by jobid on hold |
| scontrol release jobid | Release the hold that you put on jobid |
Need to run multiple jobs in sequence?
In sequence or serially
- Option 1: Submit jobs as soon as previous jobs complete
- Option 2: Submit jobs with a dependency
sbatch --dependency=afterok:<JobID> <Submit Script>In parallel, use GNU Parallel
Additional Help & Information
- Issue with running jobs or need help to get started:
- Open a help ticket: http://lehigh.edu/help
- More Information
- Subscribe
- HPC Training Google Groups: hpctraining-list+subscribe@lehigh.edu
- Research Computing Mailing List: https://lists.lehigh.edu/mailman/listinfo/hpc-l
- My contact info
- eMail: alp514@lehigh.edu
- Tel: (610) 758-6735
- Location: Room 296, EWFM Computing Center ( Remote in Fall 2020)
- My Schedule